In a complex distributed system, things will go wrong. Servers will fail, network links will experience congestion, and third-party APIs will go offline. Traditional testing focuses on whether the system works under 'normal' conditions. **Chaos Engineering** asks a different question: how does the system behave when things break? In 2025, the standard for professional B2B software is to be 'antifragile'—not just surviving failure, but getting stronger by learning from it. At All IT Solutions, we're helping our clients build these resilient frameworks through systematic 'controlled experiments' on their infrastructure.
The Core of Resilience: Hypothesis and Failure Injection
Chaos Engineering is not about breaking things randomly; it's a disciplined, scientific process. We start by defining a 'steady state'—a set of metrics that represent a healthy system (e.g., P99 **Latency** under 200ms). We then formulate a hypothesis: 'even if we lose an entire availability zone, our latency will remain within our SLO.' Finally, we conduct an experiment by injecting a specific failure into a small, controlled portion of the system.
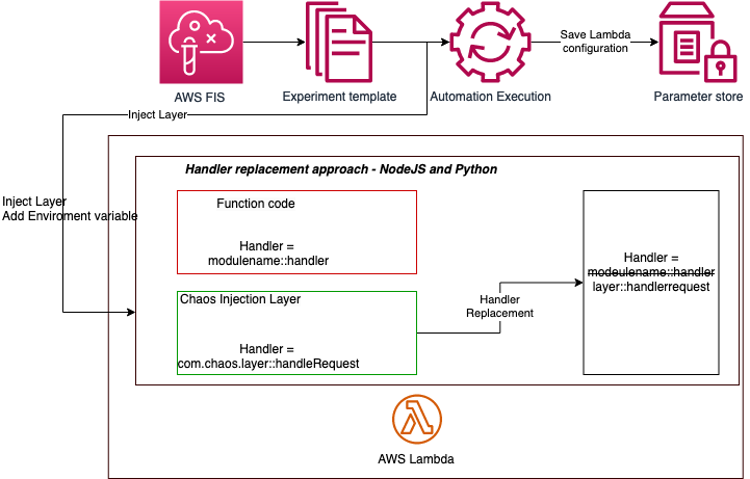
Technical execution involves the use of specialized chaos engineering tools (like Gremlin, Chaos Mesh, or AWS Fault Injection Simulator). These tools allow us to simulate network latency, CPU spikes, disk failures, and even regional cloud outages. At All IT Solutions Services, we specialize in designing these 'safety-first' chaos experiments, ensuring that your resilience testing doesn't cause an actual production incident. Visit All IT Solutions Services for more info on our SRE consulting.
Orchestrating the Chaos: The Blast Radius and Game Days
A critical concept in chaos engineering is the **Blast Radius**—the potential impact of an experiment. We always start with the smallest possible blast radius (e.g., a single container) and only increase it as the system proves its resilience. This **Orchestration** of failure allows for the safe and systematic hardening of your entire architecture.
This culminates in 'Game Days'—cross-team exercises where we simulate complex, multi-system failures to test not just the technology, but also the response of our people and processes. Our team at All IT Solutions focuses on building these 'reliability-first' cultures, ensuring that your engineering teams are prepared for the unexpected. We also perform deep-dive audits to identify and resolve any **Latency** issues that were uncovered during chaos testing. For more on our performance engineering services, visit All IT Solutions Services.
Latency vs. Resilience: The Timeout Challenge
Many system failures manifest as increased latency rather than total outages. We use chaos experiments to identify 'latent dependencies'—services that, when slow, cause cascading failures across the entire application. By optimizing timeouts, implementing circuit breakers, and using bulkhead patterns, we ensure that your system remains responsive even when some of its components are struggling.
Implementing the Zero-Trust Pillar in Chaos Operations
As chaos engineering tools have the power to negatively impact your infrastructure, they must be secured using a **Zero-Trust** model. Access to the chaos management console and the ability to run experiments should be strictly controlled with granular permissions. We implement mutual TLS (mTLS) for all communication between your chaos agents and the core infrastructure.
We also incorporate security signals into our wider chaos monitoring. A chaos experiment could potentially reveal a security vulnerability—for example, a secondary authentication server that doesn't enforce the same strict policies as the primary one. By integrating security analysis into your recovery playbooks, we provide an additional layer of protection for your enterprise assets. Security is at the heart of our consulting services, and we ensure that your automated future is built on a foundation of trust and resilience. Visit All IT Solutions Services for a review of our digital security offerings. Contact All IT Solutions today to discuss your chaos engineering strategy.
Conclusion: Standardizing the Antifragile Future
Chaos engineering is the key to building systems that you can truly rely on. By proactively testing your system's limits and automating your recovery cycles, you can move from a posture of 'hoping for the best' to one of 'prepared for the worst.' At All IT Solutions, we are dedicated to helping our clients achieve the operational excellence required for a successful digital business.
Frequently Asked Questions
Answers based on this article.
Post Tags
